

Distributed computing: computación distribuida para infraestructuras digitales eficientes

La computación distribuida ha pasado a ser una parte esencial de nuestra vida cotidiana digital, tanto en el ocio como en el trabajo. Solo con acceder a internet y realizar una búsqueda en Google, ya estás usando la computación distribuida. Las arquitecturas de sistemas distribuidos se utilizan en muchos ámbitos empresariales y proporcionan suficiente capacidad de computación y procesamiento a innumerables servicios y prestaciones. Aquí te contamos cómo funcionan, y te presentamos las arquitecturas de sistema que se utilizan y sus áreas de aplicación. También te explicamos las ventajas de la computación distribuida.
Distributed computing:¿Qué es?
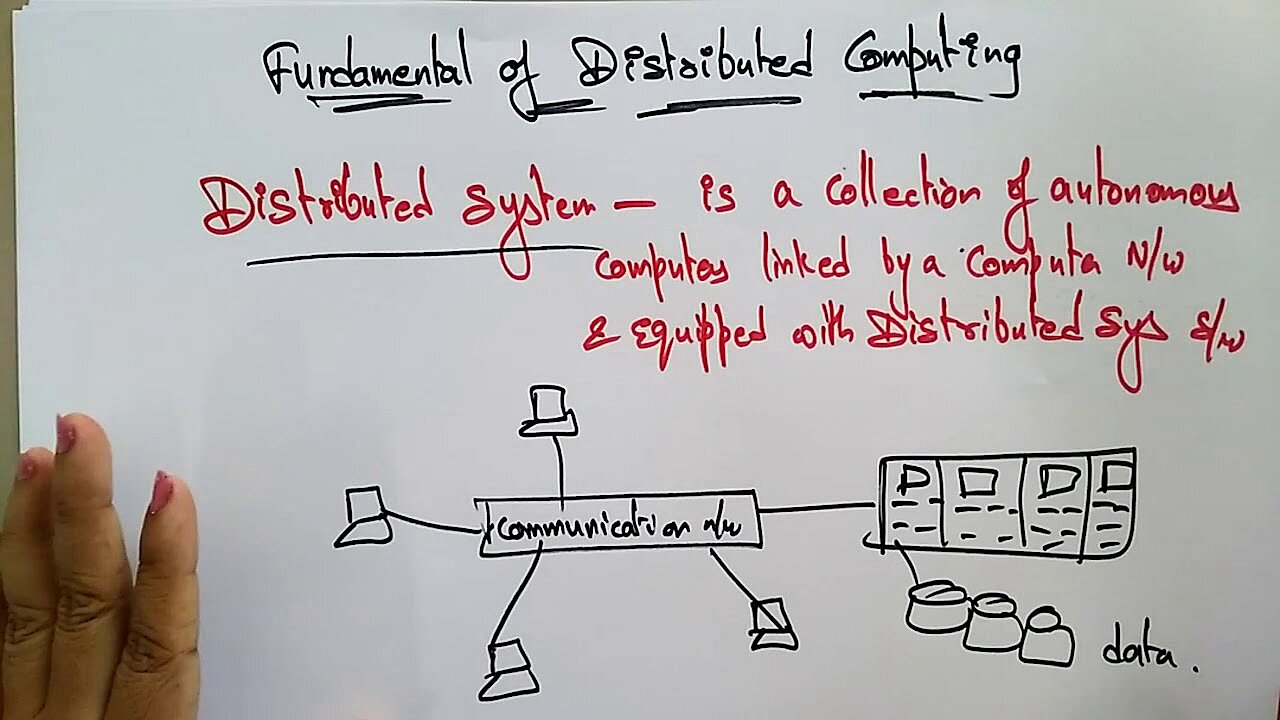
El término “computación distribuida” (en inglés, distributed computing) describe una infraestructura digital en la que una red de ordenadores conectados resuelve tareas computacionales entrantes. A pesar de que estén separados en el espacio, los ordenadores autónomos funcionan en estrecha colaboración en un proceso basado en la división de tareas. Además de los ordenadores y estaciones de trabajo más potentes del sector profesional, también pueden integrarse miniordenadores y ordenadores de escritorio de usuarios domésticos.
Al estar físicamente separado, el hardware distribuido no puede utilizar una memoria compartida, así que los ordenadores participantes transmiten mensajes y datos (por ejemplo, resultados de los cálculos) a través de una red. La comunicación entre máquinas tiene lugar a nivel local mediante una intranet (por ejemplo, en un centro de computación) o a nivel nacional y mundial a través de internet. El transporte de los mensajes se lleva a cabo mediante protocolos de internet como TCP/IP y UDP.
De acuerdo con el principio de transparencia, la computación distribuida debe presentarse al mundo exterior como una unidad funcional y simplificar al máximo su funcionamiento a nivel técnico. Los usuarios que, por ejemplo, inician una búsqueda de productos en la base de datos de una tienda en línea perciben la experiencia de compra como un proceso coherente y no tienen que lidiar con la arquitectura de sistema modular utilizada.
En última instancia, la computación distribuida es una combinación de distribución de tareas e interacción coordinada. Su objetivo es optimizar la gestión de las tareas y encontrar soluciones prácticas y flexibles.
¿Cómo funciona la computación distribuida?
El punto de partida de un cálculo realizado en computación distribuida es una estrategia especial de resolución de problemas. Un problema único se subdivide y cada parte es procesada por una unidad de computación. Las aplicaciones distribuidas (distributed applications), que se ejecutan en todas las máquinas de la red informática, se encargan de la implementación operativa.
Las aplicaciones distribuidas suelen utilizar una arquitectura cliente-servidor. El cliente y el servidor se dividen el trabajo y cubren las funciones de la aplicación con el software allí instalado. La búsqueda de productos se realiza en los siguientes pasos: el cliente actúa como instancia de entrada e interfaz de usuario, que recibe la solicitud del usuario y la prepara para que pueda pasar a un servidor. El servidor remoto se hace cargo de la mayor parte de la funcionalidad de búsqueda y busca en una base de datos. En el servidor, se da formato al resultado de la búsqueda, y este se devuelve al cliente a través de la red. El resultado final se muestra en la pantalla del usuario.
Los servicios de middleware se emplean a menudo en los procesos distribuidos. Como capa especial de software, el middleware define el patrón de interacción (lógico) entre los participantes y asegura la mediación y la integración óptima en el sistema distribuido. Así pues, se ofrecen interfaces y servicios que cierran las brechas entre las diferentes aplicaciones y permiten y supervisan su comunicación (por ejemplo, mediante controladores de comunicaciones). Para el procesamiento operativo, el middleware proporciona, por ejemplo, la llamada a procedimiento remoto o remote procedure call (RPC), un método probado de comunicación interprocesos entre dispositivos, que suele utilizarse en las arquitecturas cliente-servidor para la búsqueda de productos con consultas a bases de datos.
Esta función de integración, que contribuye al principio de transparencia, también puede describirse como una tarea de traducción. Sistemas y plataformas de aplicación técnicamente diferentes, que normalmente no pueden comunicarse entre sí, encuentran un idioma común, por así decirlo, y trabajan juntos de manera productiva con la mediación del middleware. Además de la interacción entre dispositivos y plataformas, el middleware se encarga de otras tareas, como la gestión de datos. Controla asimismo el acceso de las aplicaciones distribuidas a las funciones y procesos de los sistemas operativos que están disponibles a nivel local en los ordenadores conectados.


 Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
¿Qué tipos de computación distribuida existen?
La computación distribuida es un fenómeno multifacético con infraestructuras que, en ocasiones, difieren mucho. Por ello, no es fácil describir todas las variantes de la computación distribuida. Sin embargo, existen tres subcampos que se describen a menudo en el ámbito de la informática:
- Computación en la nube o cloud computing
- Computación en malla o grid computing
- Computación en clúster o cluster computing
En la computación en la nube, se utiliza la computación distribuida para proporcionar a los clientes infraestructuras y plataformas altamente escalables y rentables. Los proveedores de la nube suelen ofrecer capacidad en forma de servicios alojados a los que se puede acceder a través de internet. En la práctica, se han establecido varios modelos de servicio:
- Software como Servicio (SaaS): con el servicio SaaS, el cliente utiliza las aplicaciones y la infraestructura asociada de un proveedor en la nube (por ejemplo, servidores, almacenamiento en línea o capacidad de computación). También puede acceder a las aplicaciones con diferentes dispositivos a través de la llamada interfaz de cliente liviano o thin client interface (por ejemplo, una aplicación web basada en el navegador). El proveedor de la nube se encarga de mantener y administrar la infraestructura subcontratada.
- Platforma como servicio (PaaS): con el servicio PaaS, se ofrece un entorno basado en la nube para el desarrollo de aplicaciones web, por ejemplo. El usuario tiene control sobre las aplicaciones proporcionadas y puede personalizar algunos parámetros, mientras que el proveedor de la nube se encarga de la infraestructura técnica de la computación distribuida.
- Infrastructure como Servicio (IaaS): con el servicio IaaS, el proveedor de la nube proporciona una infraestructura técnica a la que los usuarios acceden a través de redes privadas o públicas. Entre los componentes de esta infraestructura se incluyen, por ejemplo, servidores, capacidades de computación y de red, dispositivos de comunicación como rúters, conmutadores o cortafuegos, espacio de almacenamiento y sistemas de archivado y protección de datos. Por su parte, el cliente controla los sistemas operativos y las aplicaciones que se le ofrecen.
La llamada computación en malla está orientada conceptualmente a la creación de un superordenador con una enorme potencia de cálculo. Sin embargo, las tareas de computación no son procesadas por una, sino por muchas instancias. Los servidores y los PC pueden realizar diferentes tareas de manera independiente. Al realizar las tareas, la computación en malla puede acceder a los recursos de manera muy flexible. En general, los participantes ponen sus capacidades informáticas a disposición de un proyecto general por la noche, cuando su infraestructura técnica se utiliza relativamente poco.
Una ventaja es que permite usar sistemas muy potentes rápidamente y escalar la potencia de computación según sea necesario. Además, no obliga a actualizar costosos superordenadores o sustituirlos por otros nuevos.
Como la computación en malla permite crear un superordenador virtual a partir de un grupo de ordenadores conectados, está especializada en problemas de computación especialmente complejos. Este método suele utilizarse para desarrollar proyectos científicos ambiciosos o para descifrar códigos criptográficos.
La computación en clúster no tiene una definición claramente distinguible de las variantes de computación en la nube y en malla. Es un término más general, que se refiere a todas las modalidades que combinan ordenadores individuales y sus capacidades informáticas en un clúster (es decir, “grupo” o “conjunto”). Por ejemplo, hay clústeres de servidores, clústeres en entornos de big data y en la nube, clústeres de bases de datos y clústeres de aplicaciones. Además, las redes informáticas se utilizan cada vez más en la computación de alto rendimiento, que resuelve problemas informáticos particularmente complejos.
También se pueden distinguir diferentes tipos de computación distribuida tomando como base las arquitecturas de los sistemas y los modelos de interacción de la infraestructura distribuida. Debido a la complejidad de las arquitecturas de sistemas de la computación distribuida, se utiliza a menudo el término “sistemas distribuidos”.
Entre los modelos de arquitectura ampliados de la computación distribuida están los siguientes:
- Modelo de cliente-servidor
- Modelo peer to peer
- Modelo de capas (arquitecturas multinivel)
- Arquitectura orientada a servicios (SOA, del inglés service-oriented architecture)
El modelo cliente-servidor es un modelo simple de interacción y comunicación en la computación distribuida. Un servidor recibe una solicitud de un cliente, realiza los procedimientos de procesamiento adecuados y envía una respuesta (mensaje, datos, resultados de los cálculos) al cliente.
La arquitectura peer to peer organiza la interacción y la comunicación de la computación distribuida a partir de aspectos descentralizados. Todos los ordenadores (también llamados nodos) tienen los mismos privilegios y realizan las mismas tareas y funciones en la red. Cada ordenador puede actuar como cliente y como servidor. Un ejemplo de arquitectura peer to peer es la blockchain de criptomonedas.
En el diseño conceptual de una arquitectura de capas, los aspectos individuales de un sistema de software se distribuyen en varias capas (en inglés, tier o layer), aumentando así la eficacia y la flexibilidad de la computación distribuida. Este tipo de arquitectura del sistema, que puede diseñarse como una arquitectura de dos, tres o n capas, según el uso previsto, es bastante común en las aplicaciones web.


Una arquitectura orientada a servicios (SOA) se centra en los servicios y en satisfacer las necesidades y procesos individuales de cada empresa. De este modo, se pueden combinar diferentes servicios en un proceso empresarial a medida. Por ejemplo, el proceso global “pedidos en línea”, en el que intervienen los servicios “entrada de pedidos”, “verificación de crédito” y “envío de factura”, está contenido en una SOA. Los componentes técnicos (servidores, bases de datos, etc.) actúan como herramientas, pero no son el centro de atención. En este concepto de computación distribuida, la prioridad es asegurara la agrupación, colaboración y organización eficaces de los servicios en aras de una gestión más eficiente y rápida de los procesos empresariales.
En la arquitectura orientada a servicios, se presta especial atención a crear interfaces bien definidas que conecten los componentes a nivel operativo y aumenten la eficiencia. Esta última también se beneficia de la versatilidad del sistema, ya que los servicios pueden utilizarse de manera flexible dependiendo del contexto y reutilizarse en otros procesos empresariales. Las arquitecturas orientadas a servicios que dependen de la computación distribuida suelen basarse en servicios web. Por ejemplo, se implementan en plataformas distribuidas como CORBA, MQSeries y J2EE.
 Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Ventajas de la computación distribuida
La computación distribuida presenta numerosas ventajas. Las empresas pueden construir una infraestructura potente y asequible que utilice ordenadores económicos con los microprocesadores habituales en vez de costosos superordenadores. Los grandes clústeres pueden incluso superar el rendimiento de un superordenador y llevar a cabo tareas de computación complejas y altamente exigentes.
Dado que las arquitecturas de sistemas de computación distribuida se componen de muchos elementos, a veces incluso redundantes, es más fácil compensar el fallo de los componentes individuales (mayor fiabilidad). En más, debido al alto grado de distribución de tareas, los procesos pueden ser subcontratados y la carga de computación compartida, permitiendo un el equilibrio de carga.
Muchas soluciones informáticas distribuidas tienen como objetivo aumentar la flexibilidad, lo que en general también aumenta la eficiencia y la rentabilidad. Para solucionar algunos problemas, se pueden integrar plataformas especializadas, como servidores de bases de datos. Por ejemplo, se pueden utilizar arquitecturas SOA en cualquier área de negocios para crear soluciones personalizadas que optimicen procesos empresariales concretos. Los proveedores pueden ofrecer capacidades e infraestructuras informáticas en todo el mundo, lo que permite el trabajo basado en la nube. Así, se pueden satisfacer las demandas de los clientes con ofertas y tarifas escalonadas y basadas en sus necesidades.
La flexibilidad de la computación distribuida ofrece la posibilidad de aprovechar capacidades temporalmente inactivas para proyectos particularmente ambiciosos. Los usuarios y las empresas también tienen flexibilidad a la hora de adquirir hardware, ya que no están atados a un solo fabricante.
Otra gran ventaja es la escalabilidad. Las empresas pueden escalar sus capacidades rápidamente y casi sin antelación o, en el caso de un crecimiento orgánico continuo, adaptar gradualmente la potencia de computación a la demanda. Si utilizas tu propio software para la escalabilidad, puedes mejorar continuamente tus equipos en pasos asequibles.
A pesar de sus muchas ventajas, la computación distribuida también tiene algunos inconvenientes, como, por ejemplo, el mayor costo de implementación y mantenimiento de una arquitectura de sistema compleja. Además, a veces se presentan problemas de tiempo y sincronización entre las instancias distribuidas, que se deben resolver. En cuanto a la fiabilidad, la estrategia descentralizada tiene algunas ventajas respecto a usar una sola instancia de procesamiento. Sin embargo, al mismo tiempo, la computación distribuida puede dar lugar a problemas de seguridad, como la transmisión de datos por redes públicas y la consiguiente vulnerabilidad frente al sabotaje y la piratería informática. Por lo general, las infraestructuras distribuidas son también más propensas a errores, ya que hay más interfaces y posibles causas de problemas a nivel de hardware y software. Asimismo, la complejidad de la infraestructura dificulta el diagnóstico de dichos problemas y errores.
¿Dónde se utiliza la computación distribuida?
La computación distribuida se ha convertido en una tecnología básica esencial para la digitalización en nuestras vidas y trabajos. Internet, y los servicios que en este se ofrecen, serían impensables sin las arquitecturas cliente-servidor de los sistemas distribuidos. La computación distribuida forma parte de todas las búsquedas de Google. Las instancias de los proveedores de todo el mundo trabajan en estrecha colaboración para generar resultados de búsqueda correctos. Google Maps y Google Earth también dependen de la computación distribuida para sus servicios.
Los procedimientos y arquitecturas de computación distribuida también se encuentran en sistemas de correo y videoconferencia, sistemas de reserva de líneas aéreas y cadenas de hoteles, bibliotecas y sistemas de navegación. Los procesos de automatización, así como los sistemas de planificación, producción y diseño en el ámbito laboral, son áreas de aplicación comunes para esta tecnología. Las redes sociales, los sistemas móviles, la banca en línea y los juegos en línea (por ejemplo, los sistemas multijugador) utilizan sistemas distribuidos eficientes.
La computación distribuida también se emplea en plataformas de aprendizaje en línea, en la inteligencia artificial y en el comercio electrónico. Los procesos de compra y pedido de las tiendas en línea se basan a menudo en sistemas distribuidos. En meteorología, los sensores y los sistemas de vigilancia dependen de las capacidades informáticas de los sistemas distribuidos para predecir catástrofes. Hoy en día, muchas aplicaciones se basan en bases de datos distribuidas.
Los proyectos de investigación particularmente exigentes en materia de informática, que antes tenían que recurrir a carísimos superordenadores (por ejemplo, ordenadores Cray), pueden realizarse ahora con los sistemas distribuidos, que son más económicos. El proyecto de computación voluntaria Seti@home, por ejemplo, marcó los estándares en el campo de la computación distribuida desde 1999 hasta 2020. Incontables ordenadores domésticos de usuarios privados, conectados en red, evaluaron los datos del radiotelescopio Arecibo de Puerto Rico y apoyaron a la Universidad de Berkeley en su búsqueda de vida extraterrestre.
Una característica especial de este proyecto era la estrategia de ahorro de recursos: el software de evaluación solo se utilizaba en períodos en los que los ordenadores de los usuarios estaban inactivos. Tras analizar la señal, los resultados se enviaban al cuartel general en Berkeley. Existen ahora proyectos comparables en otras universidades e institutos de todo el mundo.
Puedes aprender los fundamentos de la computación distribuida en el canal de YouTube Education 4u, que ofrece varios vídeos explicativos.