

Marcado de datos con JSON-LD según Schema.org

Los datos estructurados ayudan a los buscadores a entender mejor la información contenida en las páginas web. La llamada anotación semántica de datos estructurados permite a los robots establecer nexos de significado e interpretar los datos de forma automática para traducirlos en otros formatos visuales. Google, hasta el momento el buscador más utilizado con diferencia, se apoya en los datos estructurados para entregar a los usuarios resultados enriquecidos en las páginas de resultados de búsqueda (SERP). ¿Cuál es la ventaja para los administradores de estas páginas? Estos resultados destacan entre el resto y aumentan la visibilidad de la oferta.
Para que esto sea posible se debe marcar la información relevante semánticamente con las consiguientes etiquetas. Con este fin, a lo largo de los años la comunidad de Internet ha ido desarrollando diversos estándares de estructuración de datos. A continuación te contamos por qué deberías priorizar a JSON-LD ante formatos alternativos como microformatos, RDFa o microdatos.
- Domina el mercado con nuestra oferta 3x1 en dominios
- Función Domain Connect para una configuración DNS simplificada gratis
- Registro privado y gratis para mayor seguridad
¿Qué es JSON-LD?
JSON-LD, acrónimo de JavaScript Object Notation for Linked Data, es un método basado en JSON para añadir datos estructurados a páginas web aunque, a diferencia de otros formatos para estructurar datos como microformatos, RDFa o microdatos, aquí el etiquetado no se realiza como anotación intercalada en el código fuente. En lugar de ello, los metadatos se implementan dentro de una etiqueta <script> separada del contenido, bien en el encabezado (<head>) o en el cuerpo (<body>) del documento HTML. Para poder hacerlo, JSON-LD se basa en la notación JSON y la amplía con una sintaxis con la cual los datos se marcan en función de esquemas de validez universal.
La especificación de JSON-LD fue elaborada por el fundador de Digital Bazaar Manu Sporny y figura como recomendación oficial del W3C desde el 16 de enero de 2014.
JSON-LD es una sintaxis recomendada por el W3C con la cual es posible integrar en el compacto formato JSON tanto datos estructurados como los esquemas para la estructuración de datos.
JSON
Este término hace referencia a la notación de objetos con JavaScript (JavaScript Oject Notation) y designa a un formato compacto y basado en texto para el intercambio de datos fácilmente interpretable tanto por personas como por máquinas. Este formato de datos es una derivación de JavaScript, aunque se puede utilizar en cualquier plataforma independientemente del lenguaje de programación utilizado. Como formato de texto para la serialización de datos estructurados (la representación de objetos programables en una secuencia), JSON suele emplearse para transferir y almacenar datos estructurados, en aplicaciones web y en aplicaciones móviles.
La sintaxis de un objeto JSON se compone fundamentalmente de pares nombre:valor entrecomillados (a excepción de los valores numéricos), separados por dos puntos y escritos entre llaves. Cada par nombre:valor suele comenzar en una nueva línea y termina con una coma, exceptuando al último par que precede a la llave de cierre y se anota sin coma:
El siguiente ejemplo ilustra el esquema básico de la sintaxis de JSON:
{
"name": "Manu Sporny",
"homepage": "http://manu.sporny.org/about/"
}En el primer fragmento de texto se incluyen los vocablos “Manu Sporny”. Una persona que los lea entiende que esta secuencia de letras, por el contexto, corresponde a un nombre propio, y que el enlace conduce a la página web del desarrollador de JSON-LD. En cambio, los navegadores y los robots de los buscadores necesitan metadatos que les ayuden a procesar estas relaciones semánticas. Esto es lo que ofrece JSON con los pares nombre:valor.
El ejemplo mostrado arriba muestra los dos elementos “name” y “homepage” con sus respectivos valores. Un programa que interpreta a una página con este objeto JSON es capaz de identificar fácilmente a “Manu Sporny” como el nombre de una persona y a “http://manu.sporny.org/about/” como su página web.
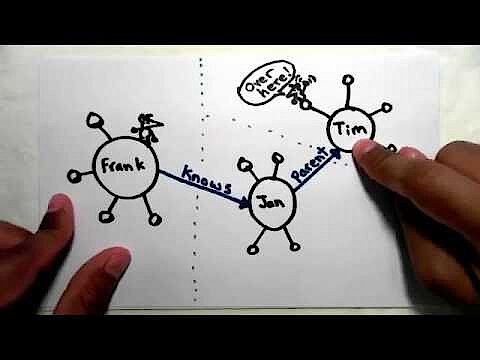
Linked Data (LD)
Si dentro de una página la asignación de significado con JSON se lleva a cabo sin problemas, no ocurre lo mismo con el análisis de datos JSON de diferentes páginas, que deriva fácilmente en un problema de ambigüedad. Por lo general, las máquinas analizan semánticamente una gran variedad de páginas web y ordenan la información que extraen de ellas en bases de datos. Pero el código usado arriba, por ejemplo, no garantiza de forma absoluta que los elementos “name” y “homepage” se utilicen en diferentes páginas web siempre en el mismo contexto. En consecuencia y para excluir ambivalencias, JSON-LD completa la clásica anotación JSON con elementos de contexto sobre la base de los datos enlazados o linked data (LD), datos estructurados conectados entre sí e identificados por URI (identificador de recursos uniforme) de forma que los rastreadores puedan “entender” las relaciones semánticas que les dan sentido.
En este vídeo, el desarrollador de JSON-LD Manu Sporny aclara en qué consisten los datos enlazados:
 Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí. Para que JSON pueda enlazar datos, JSON-LD completa los clásicos pares nombre:valor propios del marcado JSON con palabras clave (keywords). En la sintaxis de JSON-LD las palabras clave siempre van precedidas de una @ y, entre ellas, @context y @type tienen especial importancia: mientras la primera define el vocabulario en que se basa el script, la segunda hace referencia al tipo de datos (esquema) del que se trata.
El proyecto Schema.org ofrece una base de datos de esquemas estandarizados para estructurar datos. En su página web los webmasters tienen acceso a un diccionario que comprende todos los tipos de datos (types) que pueden utilizarse así como las propiedades (properties) subordinadas a cada tipo y que facilitan un etiquetado semántico aún más detallado del contenido.
JSON-LD no se asocia en principio a ningún vocabulario en especial, si bien el proyecto Schema.org, desarrollado en colaboración por los principales buscadores Bing, Google y Yahoo!, está considerado de facto como el estándar para la anotación semántica.
Si añadimos al ejemplo anterior las etiquetas semánticas correspondientes, resulta el siguiente script:
{
"@context": "http://schema.org/",
"@type": "Person",
"name": "Manu Sporny",
"url": "http://manu.sporny.org/about/"
}La keyword @context en la línea 2 define el diccionario que se utiliza para marcar los datos, en este caso Schema.org. En la línea 3 se introduce el tipo de dato “Person” con ayuda de la palabra clave @type, que se especifica un poco más en las líneas 4 y 5 con las propiedades “name” y “url”. Un programa que indexe este código puede identificar el elemento de texto “Manu Sporny” marcado como “name” como el nombre de una persona según le indica el tipo “Person” de Schema.org. Los pares nombre:valor encabezados por “name” y “url” se procesan como propiedades (properties) del esquema “Person”. El esquema de Schema.org establece qué características corresponden a cada tipo.
 Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí. Ventajas de JSON-LD frente a otros formatos de datos
La asignación de esquemas y propiedades en JSON-LD funciona de forma análoga a otros formatos para el marcado semántico de contenidos web. Convertido a código fuente, el script del ejemplo también se puede marcar con microdatos o RDFa siguiendo a Schema.org sin que resulte en una pérdida de información:
Sintaxis de microdatos según Schema.org:
<div itemscope itemtype="http://schema.org/Person">
<span itemprop="name">Manu Sporny</span>
<span itemprop="url">http://manu.sporny.org/about/</span>
</div>Sintaxis RDFa según Schema.org:
<div vocab="http://schema.org/" typeof="Person">
<span property="name">Manu Sporny</span>
<span property="url">http://manu.sporny.org/about/</span>
</div>Con todo, la gran ventaja que ofrece JSON-LD frente al resto de formatos rivales es que los metadatos no se integran en el código HTML, sino que se pueden implementar como un bloque de código autónomo en el lugar que interese. Esto se realiza mediante una etiqueta <script> siguiendo el siguiente esquema:
<script type="application/ld+json">
{
JSON-LD
}
</script>Si utilizamos nuestro ejemplo obtenemos la siguiente anotación:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Person",
"name": "Manu Sporny",
"url": "http://manu.sporny.org/about/"
}
</script>Aun cuando JSON se anota en etiquetas script, no constituye código ejecutable.
Esta estricta separación entre código HTML, por un lado, y anotación semántica, por el otro, no solamente contribuye a que el código sea más fácil de leer, sino que además posibilita la generación dinámica de estructuras de datos independientemente del contenido visible: con JSON-LD, introducir, extraer de una base de datos o generar metadatos a partir de una plantilla son acciones que pueden hacerse en el backend. Esto permite también el marcado semántico de los contenidos dinámicos, cuya demanda de espacio en Internet es cada vez mayor.
- Tráfico ilimitado, certificado SSL y firewall incluidos
- Alojado en nuestros centros de datos en España
- Soporte experto 24/7 en español
JSON-LD y SEO
Si el proyecto Schema.org no oculta su predilección por JSON-LD como uno de los formatos de datos más relevantes ya desde junio de 2013, Google recomienda la integración de metadatos con JSON-LD siempre que sea posible por constituir el fundamento de diversos elementos de las SERP (Search Engine Results Pages) que el buscador utiliza para presentar resultados ampliados a sus búsquedas.
A la hora de mostrar sus resultados, Google utiliza diferentes formatos: además de los basic results o resultados simples, desde hace algunos años los usuarios del buscador también obtienen, en función de su consulta, los llamados featured results (resultados destacados) y los knowledge graph results (resultados con gráfico de conocimiento). Mientras que los resultados simples solo se ven ampliados con breadcrumbs como único complemento, los resultados destacados y los gráficos de conocimiento son capaces de admitir más datos extra, lo que Google denomina también Enhancements o Search Results Features.
En la terminología de Google, el término Featured Result se utiliza para denominar a los resultados ampliados que presentan contenido procedente de una sola fuente (la página web enlazada). A los elementos de este tipo también se les conoce como Rich Search Result y Rich Card (tarjeta enriquecida). Si un resultado destacado permite la interacción pasa a conocerse como Enriched Search Result (resultado enriquecido). Para elaborar los gráficos de conocimiento, por el contrario, Google no se apoya en una única web, sino en el Knowledge Graph, un algoritmo que sintetiza contenido desde diferentes fuentes dando forma a resultados que también se conocen como tarjetas, cajas o cuadros de gráfico de conocimiento (Knowledge Graph Cards, Knowledge Graph Boxes, Knowledge Graph Displays). Cuando el buscador encuentra diferentes tarjetas enriquecidas o gráficos de conocimiento para una misma consulta, las muestra en forma de carrusel, un tipo de lista en forma de carrete que sirve para mostrar tipos de datos diferentes.
En la actualidad Google soporta marcas JSON-LD para las extensiones que siguen a continuación. En la galería de búsqueda de developers.google.com el proveedor presenta un ejemplo para cada formato destacado.
- Breadcrumbs: la llamada navegación con migas de pan muestra la posición de la página actual en la jerarquía de la página web. Si su administrador web marca las migas de pan semánticamente facilita que Google la pueda mostrar en la página de resultados. Las breadcrumbs se cuentan entre los pocos elementos distintivos (Search result features) que Google también incluye en los resultados simples.
- Datos de contacto corporativos: si las empresas marcan semánticamente su información de contacto, Google puede mostrarla en las SERP como Knowledge Graph Display, uno de los formatos visuales que hace posible el algoritmo de gráfico de conocimiento.
- Logotipos: cuando se marcan los logos, se deja claro al buscador qué gráfico ha de utilizar como logo corporativo oficial. Es lo que permite a Google ampliar los resultados de búsqueda de una empresa con su correspondiente logo.
- Cuadro de búsquedas para vínculos de sitios (sitelinks searchbox): hay páginas que tienen un buscador propio. Si está etiquetado semánticamente, Google lo incluye en el resultado de búsqueda de la página para consultar su contenido directamente desde aquí.
- Vínculos a perfiles sociales: si se han marcado los enlaces a los perfiles sociales como datos estructurados, Google amplía el Knowledge Graph Display de personas y organizaciones con los botones correspondientes. Por ahora Google soporta el marcado JSON-LD para Facebook, Twitter, Google+, Instagram, YouTube, LinkedIn, Myspace, Pinterest, SoundCloud y Tumblr.
Los propietarios de páginas web que aspiran a colocar su contenido en las SERP de forma prominente cuentan con la opción de identificar semánticamente distintos tipos de datos, aunque se ha de tener en cuenta que es Google quien decide en última instancia si un resultado de búsqueda se muestra como resultado simple o enriquecido. Google soporta hasta ahora la anotación JSON-LD para los siguientes tipos de datos y la utiliza para procesarlos como Rich Search Results, Enriched Search Results o Knowledge Graph Results:
- Artículos: identificando semánticamente los artículos periodísticos o las entradas de blog los webmasters permiten que Google los incorpore en el carrusel de historias principales (Top stories carousel) o los complemente en las SERP con Search Result Features como titulares o imágenes de vista previa.
- Libros: cuando una web ofrece un marcado JSON-LD para la información que hace referencia a libros Google crea una tarjeta gráfica de conocimiento para las consultas relevantes que no solo contiene datos interesantes sobre el libro, sino que también permite adquirirlo directamente desde el buscador.
- Música (músicos y álbumes): la oferta musical también se puede marcar de forma parecida, lo que permite a Google crear tarjetas gráficas de conocimiento para contenido musical que ofrecen al usuario datos sobre álbumes y músicos a la par que permiten interactuar con el contenido reproduciéndolo o incluso adquiriéndolo.
- Cursos: cuando se ofrece oferta educativa en la web y se marca con JSON-LD de forma que el rastreador pueda leer automáticamente el título, una breve descripción y el ofertante, se obtiene la ventaja de que Google muestre esta información como resultado enriquecido.
- Eventos: los organizadores de conciertos y festivales tienen la posibilidad de etiquetar con JSON-LD todos los datos relevantes relativos al lugar, la fecha y la hora del evento de tal forma que Google pueda extraerlos y enumerarlos automáticamente en las SERP o en los mapas.
- Ofertas de trabajo: las vacantes que las empresas y las organizaciones publican en su web también se pueden marcar de esta forma para mostrarlos como resultados enriquecidos.
- Negocios locales: los comerciantes de ámbito local que ofrecen datos estructurados en su página permiten que Google pueda crear tarjetas enriquecidas que se muestren en las SERP o en los mapas para las búsquedas relevantes. Si un usuario busca un restaurante asiático en Google, el buscador reproduce un carrusel con las ofertas pertinentes de la zona.
- Conjuntos de datos: las bases de datos como las tablas en CSV o los archivos en formatos propietarios también pueden hacerse accesibles al motor de búsqueda con JSON-LD.
- Podcasts: Google soporta JSON-LD también para marcar los datos sobre podcasts. Si se hace, el motor de búsqueda lo muestra como contenido enriquecido.
- Vídeos: los proveedores de contenido que ofrecen datos estructurados, tales como la descripción, un enlace a una imagen de vista previa, la fecha de su subida o su duración, para los vídeos que publican en sus páginas web, posibilitan que Google extraiga esta información y la presente como tarjeta enriquecida o como un carrusel.
- Películas y espectáculos: si una web entrega datos estructurados sobre oferta cinematográfica o espectáculos, Google los incorpora como tarjeta gráfica enriquecida cuando son relevantes para la búsqueda. Estas tarjetas pueden ampliarse con elementos interactivos que permiten consumir o adquirir la oferta.
- Recetas de cocina: desde hace algunos años, Google también ofrece recetas gastronómicas como resultado destacado. El único requisito consiste en ofrecer toda la información relevante que compone una receta como datos estructurados. Un posible formato resultante podría ser un carrusel compuesto por las tarjetas enriquecidas pertinentes para la búsqueda.
- Críticas: Google soporta valoraciones para diversos tipos de datos Schema.org como negocios locales, restaurantes, productos, libros, películas u obras creativas y su representación visual tiene lugar como snippet (recorte). Google diferencia entre las críticas de autores aislados y los comentarios en portales de valoraciones. Si han sido anotados semánticamente, ambos tipos de crítica se muestran como resultado destacado en las SERP.
- Productos: los comerciantes online que proveen los datos sobre sus artículos como el precio, la disponibilidad o las valoraciones como datos estructurados permiten que Google muestre esta información como resultados enriquecidos en búsquedas coincidentes.
Los resultados enriquecidos, ya se trate de featured results o Knowledge Graph Displays, presentan sobre todo una ventaja para los administradores web, y es que destacan de entre todos los demás resultados. Google dispone los cuadros gráficos y los carruseles en un lugar preeminente encima de los resultados simples, es decir, al principio de la página. Los Knowledge Graph Displays pueden aparecer también como carrusel en el borde superior o a la derecha de los resultados orgánicos enmarcados en un cuadro. Es así como los resultados enriquecidos ofrecen la oportunidad de alcanzar la mejor posición de la página de resultados sin invertir mucho tiempo y dinero en la mejora del ranking orgánico.
Aun así, no solo el mejor posicionamiento, sino también algunos elementos como las imágenes de vista previa, las puntuaciones, los fragmentos de texto y los elementos interactivos captan la atención del internauta y promueven las ganas de pinchar en los enlaces. Se puede asumir sin duda que la tasa de clics en los resultados enriquecidos es más elevada que en los resultados simples.
También en cuanto a la tasa de rebote puede deducirse un efecto positivo de los resultados ampliados. A diferencia de los basic results, que generalmente solo incluyen un metatítulo, un URL y una breve descripción, los resultados enriquecidos permiten hacerse una idea más detallada del contenido que puede esperarse de la página web enlazada, de tal modo que ya antes de abrirla puede probarse su relevancia para con la consulta realizada y solo pulsar en el enlace si es realmente necesario.
Con todo, Google no considera la presencia o la ausencia de marcado semántico con JSON-LD como un factor de ranking, como puso de relieve ya en 2012 Matt Cutts, exjefe del equipo de spam de Google Web, en el siguiente vídeo incluido en la serie Google Webmasters:
 Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí.
Para mostrar este video, se requieren cookies de terceros. Puede acceder y cambiar sus ajustes de cookies aquí. Tal y como la concentración del marcado en bloques de script separados propia de JSON-LD le aventaja ante otros formatos, también lo hace en el indexado de páginas. En comparación con métodos alternativos de anotación como microdatos o RDFa, JSON-LD facilita que el código fuente sea liviano y que los bots de Google y otros rastreadores los puedan explorar e indexar fácilmente. Sin embargo, esto mismo también tiene sus desventajas. En Google y otros buscadores se suele considerar como regla fundamental marcar como contenido legible para las máquinas solo aquel que también se pone a disposición del usuario, pero con JSON-LD, en cambio, se puede implementar teóricamente cualquier marcado, incluso cuando en el contenido mismo de la web no existe ningún equivalente para los metadatos que se han seleccionado. En este caso se está prometiendo, tanto al motor de búsqueda como al usuario, un hipotético valor añadido que una página así configurada en realidad no ofrece. Haciendo uso de este método se corre el riesgo de ser sancionado como medida contra el spam web.
Con el fin de evitar que los webmasters sobrepasen involuntariamente los límites de la anotación semántica conforme con los buscadores, Google provee con las Structured Data General Guidelines un conjunto de reglas que, reduciéndolo a lo esencial, podemos sintetizar en los siguientes puntos:
- Formato: los datos han de estar estructurados en función de uno de los tres formatos consolidados, estos son, microdatos, RDFa o JSON-LD. Google recomienda el último.
- Accesibilidad: las páginas con datos estructurados deben ser accesibles para el Googlebot. Los métodos que controlan su acceso (robots.txt o noindex) impiden la lectura de los metadatos.
- Equivalencia de contenido: la anotación JSON-LD solo puede describir entidades que también se describen en el código HTML.
- Relevancia: una anotación JSON-LD solo debería tomar como referencia las correspondencias relevantes de los tipos de datos utilizados. Si se marca un manual técnico como receta se infringe la directiva de relevancia.
- Integridad: todos los tipos de datos representados en la anotación JSON-LD se han de marcar de forma íntegra y con las propiedades necesarias. Los tipos de datos que carecen de propiedades esenciales no se ajustan a los resultados enriquecidos.
- Especificidad: los proyectos de datos enlazados como Schema.org ofrecen una gran diversidad de tipos de datos. Con el fin de clasificar el contenido para una representación ampliada en los resultados de búsqueda hay que escoger los esquemas tan específicamente como sea posible.
Básicamente, se considera que cuantas más propiedades se faciliten en forma de datos estructurados más elevado es el valor añadido para el usuario. En consecuencia, a la hora de posicionar las tarjetas enriquecidas Google tiene en cuenta la amplitud de los datos provistos, si bien también los webmasters se benefician de una anotación lo más completa posible. Tomando el ejemplo de las ofertas de trabajo, los usuarios prefieren encontrar aquellas vacantes que incluyan datos como el salario o valoraciones.
JSON-LD según Schema.org: manual «paso a paso»
A continuación mostramos cómo puedes enriquecer tu página web con metadatos relevantes. Este tutorial de JSON-LD se basa en el vocabulario provisto por el proyecto Schema.org.
1. Reflexiones previas
El mayor o menor trabajo derivado de la implementación de datos estructurados depende de la amplitud de la oferta web, por tanto, es recomendable pensar con antelación qué objetivos se quieren alcanzar con la anotación semántica y cuánto tiempo se está dispuesto a invertir para ello.
La anotación ha de estructurar los datos de la página web y ofrecerlos en una forma que puedan leer los motores de búsqueda, pues lo que se quiere demostrar es que esta página, optimizada de esta forma, provee los mejores recursos para búsquedas relevantes sobre la especialidad temática del proyecto. Por tanto, intenta responder a estas preguntas:
- ¿Cuál es el contenido principal de tu página web?
- ¿Qué valor añadido ofrece este contenido a las visitas potenciales?
- ¿Qué textos son tan relevantes temáticamente en relación con el foco de la web que deberían anotarse de una forma amigable para los buscadores?
2. Determina los textos más relevantes
Elabora una lista de todo aquel contenido que ofrece un valor añadido y decide sobre qué artículos sería conveniente llamar la atención del lector en potencia ya en las páginas de resultados.
Google propone, por ejemplo, anotar con JSON-LD los datos que hacen referencia a eventos. En HTML las noticias sobre conciertos, obras de teatro musical o representaciones teatrales se representan así:
<p>
<a href="http://www.example.org/zambini/2017-11-20-2000">El gran Zambini – una noche llena de magia</a>,<br>
Vuelva a adentrarse en una noche fantástica de la mano del gran Zambini, esta vez con la compañía de Max el Cuervo y la elástica Sonja.<br>
Fecha: 20.11.2017,<br>
Apertura de puertas: 20:00 h,<br>
Show: 20:30 — 23:00,
<a href="http://www.example.org/events/zambini/2017-11-20-2000/tickets">Entradas</a><br>
Precio: 100 euros,<br>
Entradas disponibles,<br>
<a href="http://www.example.org">Montaña Mágica</a>,<br>
Avda. Montaña Magica, 1,<br>
12345 Villa Magia,<br>
</p>La información más típica que comprende el objeto “Evento” hace referencia a la fecha y la hora, el precio, la disponibilidad de entradas, la dirección o los enlaces a información complementaria sobre el evento o el lugar donde tiene lugar. Los usuarios humanos son capaces de extraer esta información de un texto, de una tabla o de cualquier formato informativo y ponerlo en su contexto, pero los programas, tales como los rastreadores de los buscadores, necesitan metadatos que les indiquen cómo han de procesar toda esta información. JSON-LD se los facilita como un formato de datos que se incluye en el código fuente en HTML de forma independiente del contenido.
Las reglas para crear anotaciones JSON-LD e integrarlas en una página web las facilita Schema.org.
3. Seleccionar los esquemas
En efecto, Schema.org ofrece a los gestores de páginas web un extenso lenguaje para estructurar datos que abarca un total de alrededor de 600 tipos que a su vez pueden especificarse con más de 860 propiedades.
A la hora de escoger los tipos más adecuados, un webmaster podría seguir dos estrategias:
- En principio podría cotejar los contenidos definidos al principio con los tipos de datos disponibles en el diccionario de Schema.org y a partir de aquí seleccionar el tipo más ajustado a cada elemento de contenido, pero este método es lento y generalmente innecesario.
- En la práctica, los webmasters suelen limitarse a un conjunto determinado de tipos. Si tu objetivo a la hora de implementar una anotación JSON-LD es sencillamente proveer datos estructurados a los motores de búsqueda, sería suficiente con que te limitaras a los tipos que Google soporta en la actualidad y que describe a fondo en la sección para desarrolladores.
Como intuyes, la segunda opción es la más recomendable precisamente porque para todos los tipos que soporta su buscador, Google ofrece una detallada documentación con una anotación de ejemplo para cada tipo.
Utiliza los ejemplos que Google facilita en su página para desarrolladores como plantilla para tus propias anotaciones.
Para poder optimizar tu web con datos estructurados no hay que descubrir América. Especialmente si aún no cuentas con mucha experiencia con la sintaxis de JSON-LD, recurrir a modelos predefinidos en lugar de escribirlos desde cero puede suponer un ahorro importante de tiempo y energía. En la documentación de Google se encuentra la siguiente anotación para eventos como ejemplo:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Event",
"name": "Jan Lieberman Concert Series: Journey in Jazz",
"startDate": "2017-04-24T19:30-08:00",
"location": {
"@type": "Place",
"name": "Santa Clara City Library, Central Park Library",
"address": {
"@type": "PostalAddress",
"streetAddress": "2635 Homestead Rd",
"addressLocality": "Santa Clara",
"postalCode": "95051",
"addressRegion": "CA",
"addressCountry": "US"
}
},
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"description": "Join us for an afternoon of Jazz with Santa Clara resident and pianist Andy Lagunoff. Complimentary food and beverages will be served.",
"endDate": "2017-04-24T23:00-08:00",
"offers": {
"@type": "Offer",
"url": "https://www.example.com/event_offer/12345_201803180430",
"price": "30",
"priceCurrency": "USD",
"availability": "http://schema.org/InStock",
"validFrom": "2017-01-20T16:20-08:00"
},
"performer": {
"@type": "PerformingGroup",
"name": "Andy Lagunoff"
}
}
</script>Las etiquetas script de apertura y cierre definen el elemento desde la línea 01 hasta la 39 como un script del tipo “application/ld+json”, lo que quiere decir que los datos que encierra se dirigen a programas con capacidad para interpretar datos enlazados en formato JSON.
En un primer nivel se encuentran las palabras clave “@context” y “@type” con los valores “http://schema.org” y “event” respectivamente (líneas 03 y 04). El programa obtiene con ellas la instrucción de que los datos que siguen pertenecen al esquema “Event” según Schema.org, es decir, se trata de propiedades específicas del evento que se describe, que se muestran como pares nombre:valor.
En este mismo nivel también aparecen las propiedades “name”, “startDate”, “location”, “image”, “description”, “enddate”, “offers” y “performer”, a las que se asignan los datos sobre el evento como valor. Es así como un rastreador del buscador puede identificar sin atisbo de duda la información “Lieberman Concert Series: Journey in Jazz” como título del show (“name”) y “2017-04-24T19:30-08:00” como el momento exacto en que tiene lugar (“startDate”).
Al igual que RDFa y microdatos, la sintaxis de JSON-LD también soporta la anidación (nesting), por la cual a una propiedad también puede asignarse un esquema secundario que a su vez puede especificarse aún más detalladamente con otras propiedades. Así lo encontramos en el segundo nivel del código en las líneas 08, 27 y 35.
En la octava línea, por ejemplo, la propiedad “location” se define como un subesquema del tipo “Place” y detallado con las propiedades “name” y “address”. Asimismo, la propiedad “address” se define en la línea 11 como subesquema del tipo “PostalAddress” y con las propiedades “streetAddress”, “addressLocality”, “postalCode”, “addressRegion” y “addressCountry”.
Cada nuevo nivel se delimita con claves para separarlo del nivel superior al que se subordina.
Fragmento (líneas 07—18):
"location": {
"@type": "Place",
"name": "Santa Clara City Library, Central Park Library",
"address": {
"@type": "PostalAddress",
"streetAddress": "2635 Homestead Rd",
"addressLocality": "Santa Clara",
"postalCode": "95051",
"addressRegion": "CA",
"addressCountry": "US"
}
},Como vemos, Schema.org pone a disposición de los webmasters los tipos de datos en una estructura de árbol que partiendo del tipo más general “Thing” (cosa) va descendiendo hacia el nivel más concreto.
En el siguiente paso mostramos cómo puedes adaptar el ejemplo de Google para “Event” a tu propio evento.
4. Modificar una anotación JSON-LD
En la documentación de Google se incluyen únicamente ejemplos que ilustran cómo marcar los tipos explicados con JSON-LD, pero si se utilizan como plantilla el código se debe ajustar a cada caso. A menudo puede resultar de gran ayuda echar un vistazo a la propia documentación de Schema.org a propósito de los tipos de datos para conocer mejor un determinado esquema así como las propiedades que se le pueden asignar. En el siguiente ejemplo puedes entender cómo se personaliza un código de Google para el tipo Event:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Event",
"name": "El gran Zambini – una noche llena de magia",
"startDate": "2017-11-20T20:00",
"url": " http://www.example.org/zambini/2017-11-20-2000",
"location": {
"@type": "Place",
"sameAs": "http://www.example.org",
"name": "Montaña Mágica",
"address": {
"@type": "PostalAddress",
"streetAddress": "Avda. Montaña Magica, 1",
"addressLocality": "Villa Magia",
"postalCode": "12345",
"addressCountry": "Magicolandia"
}
},
"image": [
"https://example.com/photos/1x1/zambini.jpg",
"https://example.com/photos/4x3/zambini.jpg",
"https://example.com/photos/16x9/zambini.jpg"
],
"description": " Vuelva a adentrarse en una noche fantástica de la mano del gran Zambini, esta vez con la compañía de Max el Cuervo y la elástica Sonja.",
"endDate": "2017-11-20T23:00",
"doorTime": "2017-11-20T20:30",
"offers": {
"@type": "Offer",
"url": "http://www.example.org/events/zambini/2017-11-20-2000/tickets ",
"price": "100",
"priceCurrency": "EUR",
"availability": "http://schema.org/InStock",
"validFrom": "2017-11-01T20:00"
},
"performer": {
"@type": "Person",
"name": "El gran Zambini"
}
}
</script>En un primer paso se han sustituido todos los valores de la plantilla por los valores del evento y eliminado o modificado aquellos esquemas y propiedades que no se ajustaban a él. Por ejemplo, en el subesquema “performer”, en lugar de “PerformingGroup” se ha utilizado “Person”, ya que el evento no está protagonizado por una banda, sino por un solo artista. Asimismo hemos ampliado la anotación con datos que el modelo de Google no incluye: en las líneas 07 y 10 se incluyen los URL del evento y del lugar donde se celebra. En la documentación de Schema.org encuentras todas las propiedades que puedes utilizar.
Incluso si escribes tu anotación desde cero es recomendable echar un vistazo a la página de la documentación de Google sobre cada tipo porque la compañía indica las propiedades que son obligatorias y las que se recomiendan para cada uno de los tipos que soporta.
Cuida que tu anotación comprenda todas las propiedades obligatorias porque solo en ese caso la página puede aspirar a clasificarse como resultado enriquecido. Intenta, además, proveer de valor a las propiedades recomendadas para incrementar tus opciones de entrar en el ranking.
Los ejemplos que incluye Google en su documentación contienen siempre todas las propiedades tanto obligatorias como opcionales. Y si quieres comprobar si falta alguna propiedad en tu anotación utiliza su propia herramienta de validación.
5. Probar la anotación JSON-LD
La anidación de esquemas, esquemas secundarios y propiedades repercute en anotaciones generalmente complejas, si bien la separación de HTML y anotación semántica repercute en una legibilidad mucho mayor que en otros formatos apoyados en código fuente. Con objeto de evitar posibles errores de programación, con la Structured Data Testing Tool Google ofrece la opción de validar gratuitamente el código JSON-LD que has escrito.
Sigue estos pasos:
- Copia y pega el código en el campo previsto para ello


Puedes copiar la anotación en el campo previsto para ello o insertar el URL de la página web cuyos metadatos quieras comprobar.
- Valida el código pulsando en “Ejecutar prueba”


Durante la comprobación, la herramienta lee los datos estructurados de la anotación JSON-LD y comprueba su integridad. Seguidamente el usuario obtiene una vista de tabla en la que se muestran los datos extraídos y que contiene avisos e indicaciones si la herramienta encuentra errores de sintaxis o si detecta que faltan datos.
Tal como vemos en la imagen, nuestro código no contiene errores e incluye todas las propiedades necesarias. Si elimináramos la propiedad obligatoria “startDate” recibiríamos la siguiente respuesta:


También se pueden localizar así errores de sintaxis como olvidar la coma al final de un par nombre:valor.


- Genera la vista previa
Además de la función de prueba, la herramienta de comprobación de Google también contiene un modo de vista previa que anticipa el aspecto que podría tener un resultado enriquecido basado en las anotaciones validadas. Para ello solo tienes que pulsar en el botón “Obtener una vista previa”.
Posibles errores en la implementación de la anotación JSON-LD
Si Google no muestra ningún resultado enriquecido a pesar de utilizar JSON-LD para marcar los datos suele deberse a un error en la estructuración de los datos, así que lo mejor sería volver a comprobar el código prestando atención especialmente a estas fuentes frecuentes de error:
- Error de sintaxis: el vocabulario de JSON-LD es sencillo y claro, pero como ocurre con cualquier lenguaje de marcado, también pueden colarse errores de vez en cuando. Un motivo frecuente de error radica en la diferencia entre los dos tipos de comilla inglesa que se usan para la programación ("…") y para la palabra impresa (“…”). Dado que los programas de procesamiento de textos a menudo transforman las primeras en comillas literarias, puedes evitarte dolores de cabeza si utilizas un editor como Notepad para escribir tu anotación JSON-LD. La comilla simple (' '), tan popular en programación, tampoco se acepta en JSON.
- Vocabulario incompleto, erróneo o poco específico: en la estructura jerárquica de Schema.org se define con exactitud qué propiedades se pueden utilizar para qué tipo de datos. Si utilizas una propiedad para un tipo no compatible Google no puede interpretar el valor correspondiente y clasifica el código como erróneo. La herramienta también descubre este tipo de errores.


Todos los tipos y propiedades del vocabulario Schema.org son case-sensitive, lo que significa que utilizar mayúscula o minúscula puede provocar diferencias semánticas significativas.
En definitiva, ten siempre a mano las páginas de documentación de Schema.org y valida el código que escribes con ayuda de la herramienta de pruebas de Google. Asimismo, conviene tener en cuenta las Pautas Generales para Datos Estructurados y las directrices para webmasters de Google con tal de evitar una infracción de la normativa que podría conducir a la exclusión del ranking para resultados enriquecidos.